使用R语言进行分词,并进行简单分析
使用tm包词频统计
文本预处理
tolower函数将所有英文字母转换为小写字母,removeNumbers函数将数字删除,removePunctuation函数将标点符号删除,removeWords函数将停用词删除,stripWhitespace函数将多余的空格删除,stemDocument函数将单词还原为其词根。
词频统计
使用TermDocumentMatrix函数将语料库对象转换为文档-单词矩阵,然后使用findFreqTerms函数找出出现频率最高的单词,使用rowSums函数统计每个单词出现的总次数。
代码实现
将分词和词频统计两部分封装成函数get_word_counts,注意传入参数text为数据库的文本列,例如tweets$text
library(tm)
get_word_counts <-function(text){
# 分词
corpus <- VCorpus(VectorSource(text))
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeWords, stopwords("english"))
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_map(corpus, stemDocument)
# 统计词频
tdm <- TermDocumentMatrix(corpus)
freq_terms <- findFreqTerms(tdm, lowfreq = 50)
word_counts <- rowSums(as.matrix(tdm))
word_counts <- sort(word_counts, decreasing = TRUE)
return(word_counts)
}
demo调用,数据集链接
tweets <- read.csv('tweets.csv')
word_counts <- get_word_counts(tweets$text)
# 输出词频前25单词
result <- data.frame(count = word_counts)
print(head(result, n = 25))
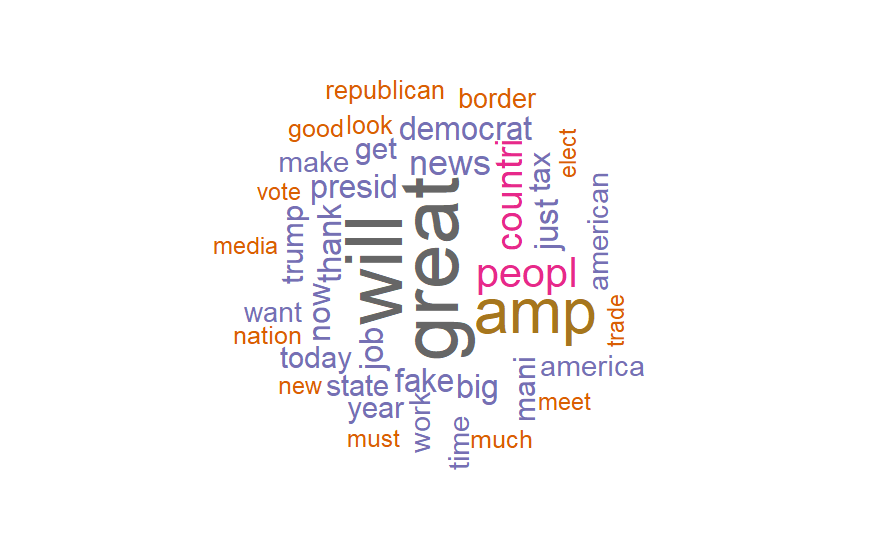
使用wordcloud绘制词云
library(wordcloud)
# 获取前40个高频单词
top_words <- head(word_counts, n = 40)
# 绘制词云
wordcloud(words = names(top_words), freq = top_words, min.freq = 1, max.words = 100, random.order = FALSE, rot.per = 0.35, colors = brewer.pal(8, "Dark2"))